LRU(Least Recently Used)
LRU(Least Recently Used),即:最近最少使用,是一种常见的置换算法;LRU算法的设计原则是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。
简单来说,就是在限定容量的cache中,当超过临界容量时,优先把近期最少使用的数据删除掉。
常见的做法是使用一个双向链表来实现
对于cache的操作来说,无非就是三种:插入、替换、查找
- 插入(insert)
- 当cache空间未满时,将新的数据放到链表的尾部节点,表明是最新访问的数据,时间复杂度是O(1)
- 替换(insert+delete)
- 当cache空间已满时,将新的数据放到链表的尾部节点,并删除链表的头节点(再重新指向链表的头节点)。时间复杂度O(1)
- 查找(lookup)
- 每当数据被访问时,都将此数据移动到链表的尾部节点。时间复杂度O(n)
但是在缓存的设计当中,查找一个缓存的操作是非常频繁的,有没有尽可能的减少缓存查找的时间复杂度呢?那么这时候就需要用到哈希表了
链表+哈希表
我们都知道哈希表的时间复杂度是O(1),哈希表的key作为缓存的key,哈希表的value为链表的节点,这样就可以让时间查询降低到O(1)

Get(Key)
当使用get(key)方法访问缓存时,将找到的元素从链表的节点更新至链表的首节点,所以被访问频率最低的元素会放在链表的尾节点上
Put(Key)
当使用put(key)时,如果链表没超过缓存最大容量设计,将需要新增的缓存放在链表的首节点上,同时在哈希表中新增一个key对应这个链表的节点;如果链表满了,则会将链表的尾节点元素移除,同时移除哈希表中对应的key,接着再将元素新增到链表的第一个,同时在hash表中建立key以及对照关系
LFU(Least Frequently Used)
LFU(Least Frequently Used),即:最不经常使用,LFU它的设想是:如果一个信息正在被访问,那么在近期它很可能还会被再次访问,所以相比于LRU算法,LFU更加注重于使用的频率
原理
LFU将数据和数据的访问频次保存在一个容器当中,当访问数据时:
- 该数据在容器中,则将该数据的访问频次+1
- 该数据不在容器中,则将该数据加入到容器中,且该数据的访问频次为1
当数据量达到容器的限制时,会剔除掉访问频次最低的数据,示意图:

LFU的实现
复杂度为O(1)的实现方案可以通过哈希表+两个双向链表来实现(也叫做十字链表):
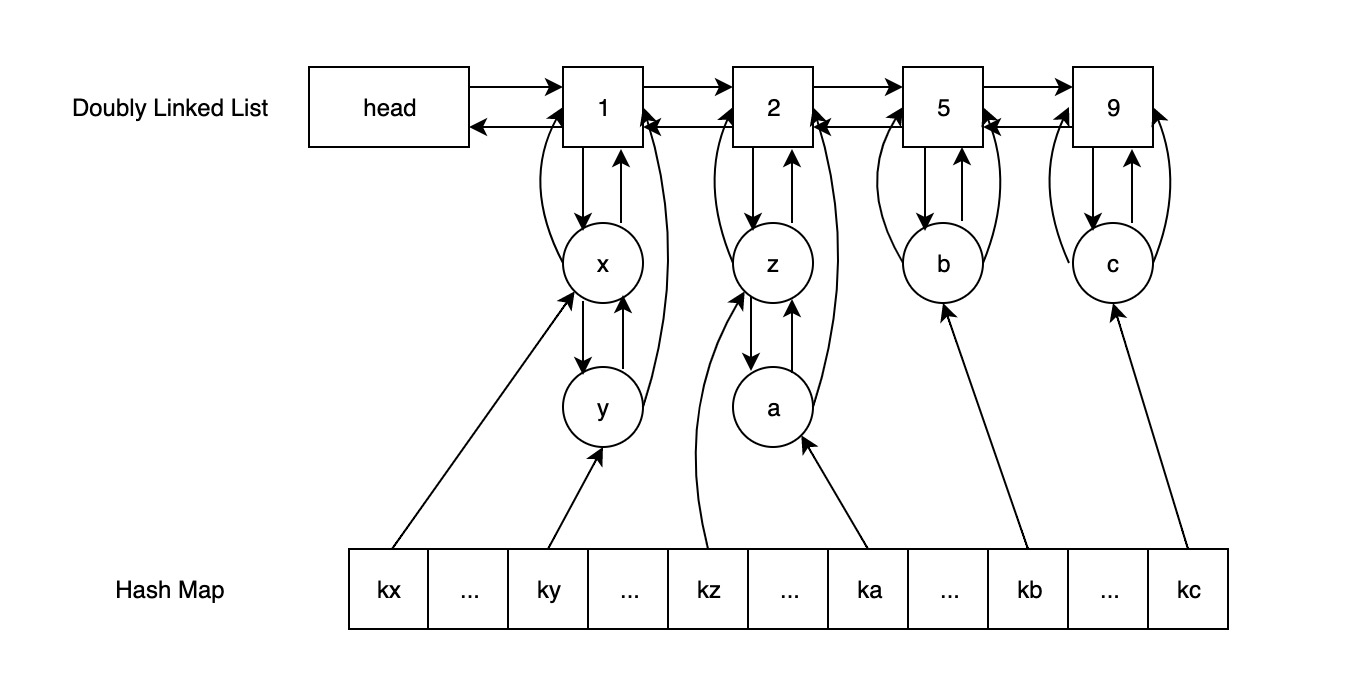
- head 与横向 Doubly Linked List 相连,后者的节点由近及远地、从低到高地存储访问频次数据
- 横向 Doubly Linked List 中的每个节点都指向一个纵向 Doubly Linked List
- 纵向 Doubly Linked List 中的节点存储的是出现频次相同的元素,且每个节点都维护着一个指向其对应的横向 Doubly Linked List 节点的指针。
以上面图为例子,哈希表中的key:kx的value指向了纵向的链表x,通过x可以找到横向链表访问频次为1,这样就能实现一个复杂度为O(1)的LFU缓存算法设计
LFU相比于LRU的优劣
两者的区别是,LFU是基于访问频次的模式,LRU是基于访问时间的模式
优劣势比较:
- 在数据访问符合正态分布时,相比于LRU算法,LFU算法的缓存命中率会高一些。
- LFU的复杂度要比LRU更高一些,但通过特殊设计可以达到O(1)的时间复杂度。
- LFU容易发生缓存抖动,如果加入新缓存元素时,此刻缓存容量即将达到饱和时,那么刚刚新加入的缓存很容易被剔除掉
本文首次发布于 孙忠良 Blog, 作者 [@sunzhongliang] , 转载请保留原文链接.