数据结构是计算机存储、组织数据的方式
本文演示代码为Swift语言
哈希表(HashTable)
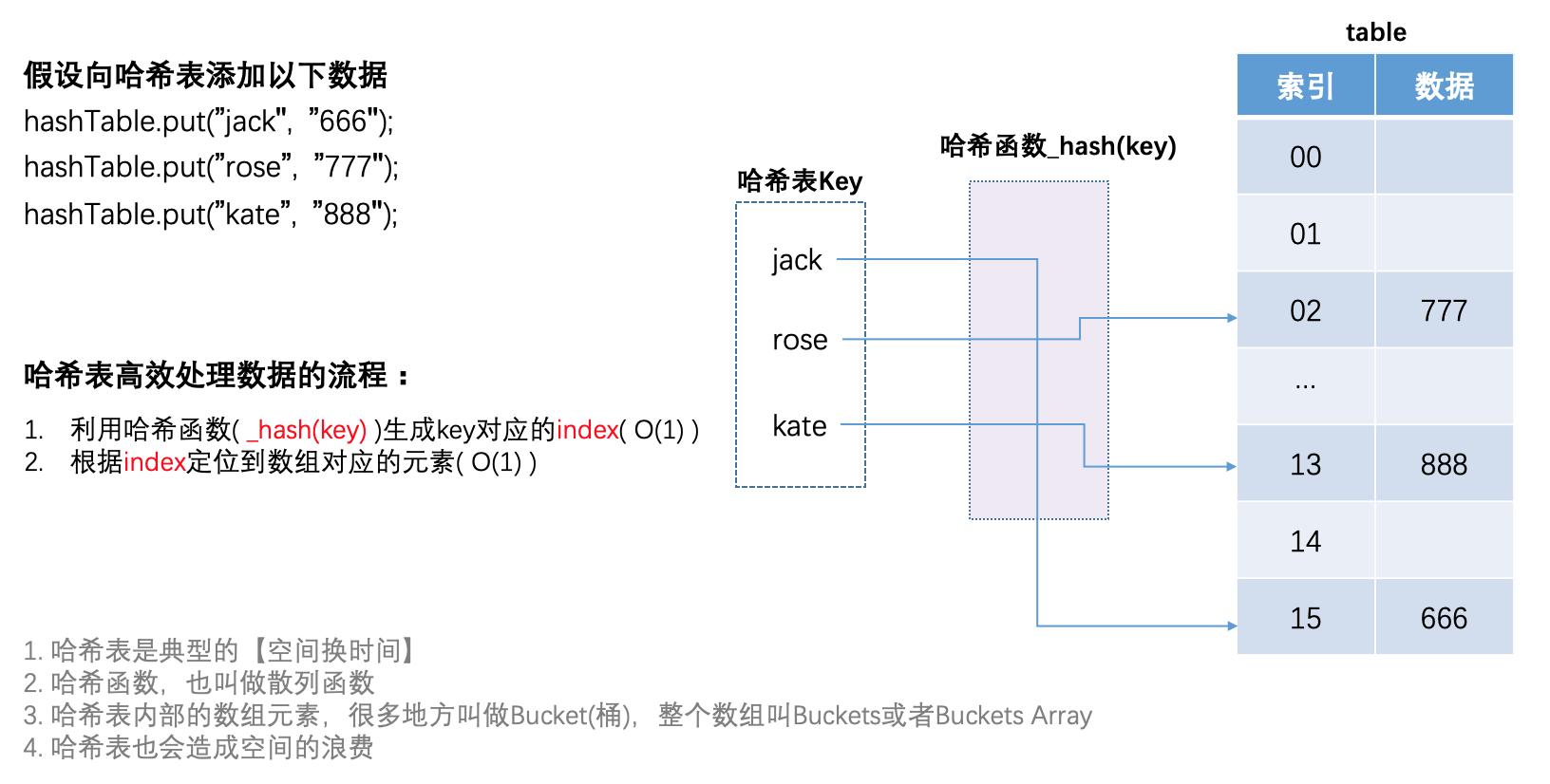
在讲HashTable先来看一个简单的需求
请设计出一个办公楼的通讯录,存放此办公楼所有公司的通讯信息,座机号码作为key(最长10位),公司详情(名称、地址)作为value,要求添加、删除、搜索的时间复杂度是O(1)级别
思考:
由于要实现O(1)复杂度的查找、添加、删除操作,常规操作可能是用一个数组来存放数据(数组的下标为电话号码,存储的信息为通讯信息),这样确实能满足需求,但势必会造成空间使用率极低,非常浪费空间(电话号码并不是连续的,且跳跃度很大)
那么有没有一种数据结构可以实现上面的需求,且空间复杂度很小的数据结构呢?
哈希表就可以
哈希表特点
哈希表也叫做散列表(hash有剁碎的意思)
它是如何实现高效率的呢?
哈希冲突(Hash Collision)
哈希冲突也叫做哈希碰撞指的是:两个不同的key,经过哈希函数计算出了相同的结果
解决哈希冲突的常见方法是:
- 开放定址法(Open Addressing)
- 按照一定规则向其他地址探测,直到遇到
空桶(当发生地址冲突时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止)
- 按照一定规则向其他地址探测,直到遇到
- 再哈希法(Re-Hashing)
- 设计多个哈希函数(对于冲突的哈希值再次进行哈希处理,直至没有哈希冲突)
- 链式地址法(Separate Chaining)
- 对于相同的哈希值,使用链表进行连接。使用数组存储每一个链表
在
java中,JDK1.8的哈希冲突解决方案默认是链式地址法,在添加元素时可能会由单向链表转为红黑树来存储元素
比如当哈希表容量>=64时且单向链表的节点数大于8时当红黑树节点数量少到一定数量时,又会转为单向链表
哈希函数
哈希表中哈希函数的实现步骤大概如下:
- 先生成
key的哈希值(必须是整数) - 再让
key的哈希值跟数组的大小进行相关运算,生成一个索引值
良好的哈希函数应当是均匀分布的
生成key的哈希值
key的常见种类可能有整数、浮点数、字符串以及自定义对象等
不同种类的key,哈希值的生成方式不一样,但目标是一致的:
1.尽量让每个key的哈希值是唯一的
2.尽量让key的所有信息参与计算
整数:
对于整数来说,可以直接将整数值作为哈希值
浮点数:
浮点数可以将存储的二进制格式转为整数值,比如10.6在内存当中的二进制格式是1000001001010011001100110011010,然后将这个二进制格式再转为int类型即可
Long和Double的哈希值:
Int类型占用4个字节,但Long类型是占8个字节的,也就是64位长度,其实也可以直接将Long类型作为哈希值。但不同平台对于hash值要求是不一样的, 比如java就要求hash值必须是Int类型,这也就要求Long类型需要转为Int类型(但也有办法是Long转为64位长度后取前32位或者后32位在转Int,但这种做法不好,因为违背了key的所有信息都参与计算的原则)
对于Long来说,java官方是这么做的:
public static int hashCode(long value) {
// 代表了将value无符号右移32位,然后再跟value做一个异或的运算
return (int)(value ^ (value >>> 32));
}
对于double(double也是8个字节,占用64位长度)来说,java官方是这么做的:
public static int hashCode(double value) {
// 将double类型的value转为long类型
long bits = doubleToLongBits(value);
// 将bits无符号右移32位,然后再跟bits做一个异或的运算
return (int)(bits ^ (bits >>> 32));
}
>>> 和 ^ 的作用是:高32bit和低32bit混合计算出32bit的哈希值
| 进行的操作 | 计算的结果 |
|---|---|
| value初始化的值 | 1111 1111 1111 1111 1111 1111 1111 1111 1011 0110 0011 1001 0110 1111 1100 1010 |
value >>> 32 进行无符号右移32位 |
0000 0000 0000 0000 0000 0000 0000 0000 1111 1111 1111 1111 1111 1111 1111 1111 |
value ^ (value >>> 32) value异或运算得到的结果 |
1111 1111 1111 1111 1111 1111 1111 1111 0100 1001 1100 0110 1001 0000 0011 0101 |
字符串的哈希值:
字符串是由若干个字符组成的, 比如jack是由j、a、c、k4个字符组成的(字符的本质就是一个整数,都对应一个ASCII值)
因此字符串jack的哈希值可以表示为j*n^3 + a*n^2 + c*n1 + k*n^0等价于[(j*n + a)*n + c]*n + k; 在JDK中,乘数n为31(31是一个奇素数,JVM会将 31*i 优化为(i « 5) - 1)
这个方程式的最终实现代码(java)是:
String string = "jack";
int len = string.length();
int hashCode = 0;
for (int i = 0; i < len; i ++) {
char c = string.charAt(i);
hashCode = hashCode * 31 + c;
}
// 对于java来说,已经帮我们实现好了string类型的hashCode方法,可以直接得到hash值
String string = "jack";
System.out.println(string.hashCode()); // 这个得到的hash值和上面我们自己生成的hash值是一样的
自定义对象:
java当中如果创建了一个自定义类型都会继承自基类Object,比如Person类,默认就可以调用父类的hashCode方法;
创建一个Person对象并在控制台打印它的hashCode方法,可以看到是有输出的。其实这个hashCode方法计算方式是跟对象的内存地址是有一定关系的(再创建一个相同的Person对象,其成员变量值也一样,但打印hashCode值可以明显的看到hashCode是不一样的)
但如果在自定义对象当中实现了hashCode方法是可以自定义hash值的实现方式的, 计算方式可以将自定义对象的所有信息参与到计算当中,最终返回出一个Int类型的hash值
// 自定义对象的hashCode计算方式
public int hashCode() {
int hashCode = Integer.hashCode(age);
hashCode = hashCode * 31 + Float.hashCode(height);
hashCode = hashCode * 31 + (name != null ? name.hashCode() : 0);
return hashCode;
}
在java中,HashMap的key必须实现hashCode,equals方法,也允许key为null
为什么要必须实现equals方法呢?原因就在于hash冲突时的判断方式是使用equals来判断的, 总结如下:
当使用自定义对象作为HashMap的key时,会使用对象的hasCode方法获取hash值去添加
- 如果HashMap中存在相同的hash值,
- 会调用对象的equals方法去做比较
- 如果不一致则在链表后面追加节点
- 如果一致则覆盖
- 会调用对象的equals方法去做比较
本文首次发布于 孙忠良 Blog, 作者 [@sunzhongliang] , 转载请保留原文链接.